Relational table based applications derive all of their content from the 2-dimensional datasource(s) they connect to, because in a tabular world, that is all there is. With OLAP systems, and TM1 specifically, there is much more there than meets the eye. Much more! There are hierarchies, aliases, attributes, consolidated business logic, cell-level security...and the list goes on. TM1Connect opens up a new world to relationally based applications to access multi-dimensional data from TM1; and conversely, TM1 data now can be surfaced outside of the IBM Cognos TM1 tools.
Bringing these two very disparate technologies together, however, is not an easy task and it is not without some level of compromise (and perhaps a little gnashing of teeth). Case in point: Title Dimensions
# Title dimensions are filters - so use them!
In the TM1 world, title dimensions, are, well, title dimensions. They allow you to pick an element for which to constrain (filter) a slice of the cube contextually based on the element selected. A relational world, however, has no true concept of this, but the closest it does have is the SQL WHERE clause. Unfortunately, the WHERE clause operates only on the visible columns of the 2 dimensional table. This is where the power of TM1Connect comes in!
In TM1Connect, you can create views of the cube that define the overall structure of the "relational table" to be returned to the querying application. At it's core, it contains the necessary rows and columns, and you can perform all the typical SQL style operations you are accustomed to having in your SQL SELECT clause, such as CASE, LEFT, MID, AVG, MIN, MAX, CONVERT, and even nested subqueries (JOINs and write-back commands, such as INSERT, however, are not yet available at the time of writing this).
Even though the results of the query have rows and columns, you still have access to the title dimension elements at runtime which can be accessed via the WHERE clause. The following diagram illustrates the basic structure of the view and how it is referenced in a standard SQL statement.
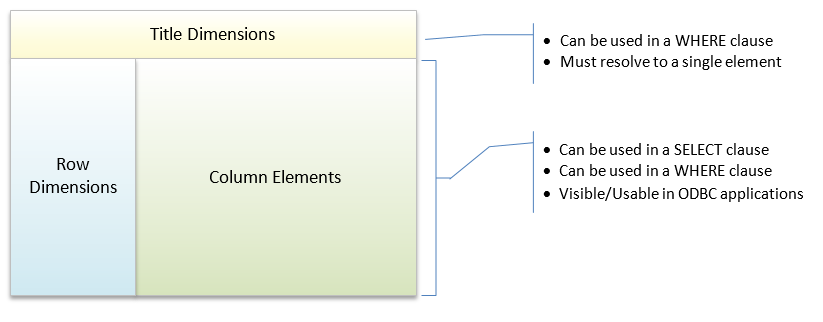
So, lets assume you have the following view set up in TM1Connect

You can reference the Department, Version and Months dimensions right in the WHERE clause! You don't need to bring them into the rows in order to be able to filter them, which bringing them into the rows would instruct TM1Connect to create a view in TM1 and pull the all the data from the cube....something that may prove to be intensive for TM1 and TM1Connect to process. With a view defined in this manner, you can then write your SQL as follows:
SELECT Employee, Salary, Benefits, Commissions
FROM Employee Reporting
WHERE Year = '2017' and Version = 'Budget' and Department = 'IT'
This query will then return the list of employees and their associated compensation information but restricted to the 2017 Budget for the IT department, as you would normally do when using the intrinsic TM1 cube viewer, but now you have that view right in your ODBC query tools!
Furthermore, in the above SQL statement, you can now specify '2017', '2017 Q1', '2017 Jan' and the results are still valid. Imagine what it would take in SQL to create a proper headcount, balance sheet account or cash flow account at varying levels of consolidation if you started with detail level data? In some cases, it cannot even be done without some sort of pre-processing or supporting tables.
Structuring your views in this manner also allows you to not only leverage the model and business logic you designed in TM1, but it allows you to create dynamic and high performing queries for your relational style reporting applications.
So why not let TM1 do what it does best, let your reporting tools do what they do best, and let TM1Connect take care of the rest!